Internal Policy & Process Knowledge Assistant
A grounded GenAI workflow for faster, more reliable answers across internal policies, procedures, and operational documents.
I built this project around a very normal operations problem: the documentation already existed, but people still struggled to use it reliably in day-to-day work.
Instead of treating that as a chatbot prompt problem, I treated it as a knowledge workflow problem. I designed a realistic internal document corpus, structured it for retrieval, introduced source-priority logic, and built a grounded answer flow that returns responses with visible evidence.
The business problem
Documentation existed. Operational confidence did not.
Northstar Operations Ltd. did not have a documentation availability problem. It had a documentation usability problem.
Policies, procedures, SOPs, and support documents were already in place, but that did not mean people could get to the right answer quickly when work was actually moving. Employees still searched across multiple files, relied on experienced colleagues who “knew where things lived,” and handled similar questions with too much variation.
The real business question was not whether GenAI could answer questions about documents. It was whether a grounded knowledge workflow could make internal documentation meaningfully more usable, reduce search friction, and improve answer consistency enough to be worth using in operations.
What this looked like in practice
- The same question could get different answers depending on who replied
- Useful documents existed, but the right one was not always the first one found
- Experienced team members became informal bottlenecks
- Confidence dropped fast when the answer had no visible source
- Small process questions still consumed time because finding the answer was harder than it should have been
Why this needed more than a chatbot
This use case sounds simple until you look at how internal answers are actually formed. A useful answer might depend on a policy, a procedure, an approval threshold, and an exception rule at the same time.
Relevance alone is not enough. The workflow also has to recognize which source is more authoritative, when FAQ content should stay secondary, and when a human question is vague enough that the answer should stay careful rather than overconfident.
What made the problem harder
- Answers often lived across more than one document
- Formal policies and FAQs did not carry the same authority
- Users asked messy, indirect questions rather than neat policy queries
- The most similar chunk was not always the most trustworthy one
- Good answer quality depended on retrieval discipline before generation
What that meant for the design
- Build a deliberate corpus, not just a pile of PDFs
- Preserve document type and source context in chunk metadata
- Prioritize formal documents above FAQ content when both match
- Return evidence with the answer so users can trust what they see
- Validate retrieval quality instead of stopping at a nice-looking demo
Corpus architecture
Retrieval quality depends heavily on corpus design. This project was stronger because the document set was not treated as a flat pile of PDFs, but as a small internal knowledge system with different levels of authority and different jobs inside the workflow.
The corpus was intentionally structured around document authority, process logic, and support content, so the answer layer had a better chance of surfacing not just something relevant, but the right kind of evidence.
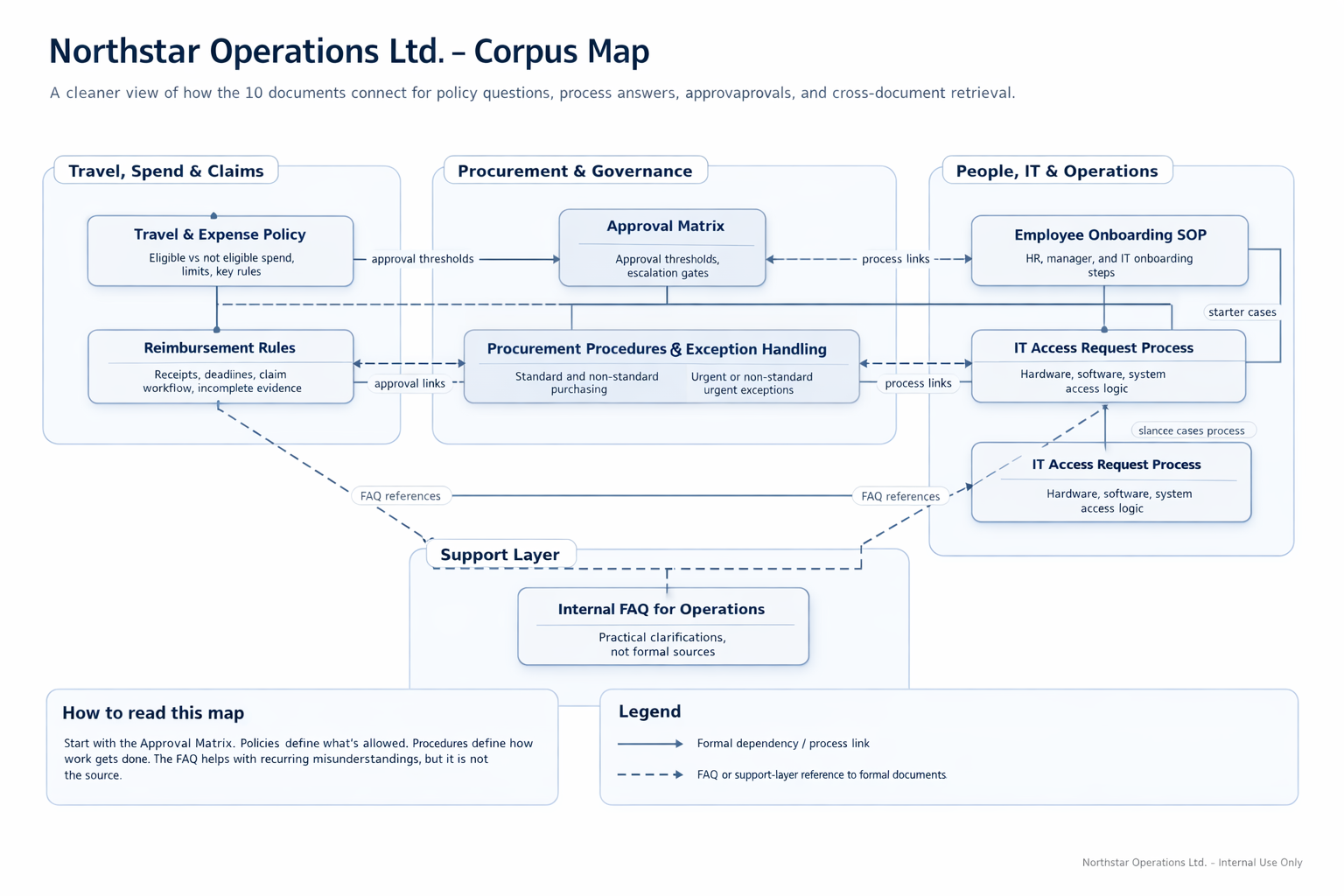
How the corpus was structured
Policies
Defined what was allowed, limited, or expected across recurring operations scenarios.
Procedures and SOPs
Defined how work actually got done step by step, especially when the answer depended on process sequencing.
Approval records and thresholds
Defined who had authority to approve, escalate, or exception-handle decisions.
FAQ support content
Helped with speed and wording, but was deliberately treated as secondary to formal sources.
How the answer gets built
The front-end answer only looks simple because the workflow underneath it is structured. This project was designed so that answer quality depended less on model fluency and more on document preparation, source control, and evidence selection.

Stage 1 — Prepare the knowledge
- PDF ingestion and text extraction
- Normalization into structured markdown
- Chunking with metadata and source anchors
Stage 2 — Retrieve the right evidence
- Retrieval against structured chunks
- Source-priority reranking
- Formal document preference over FAQ content when both are relevant
Stage 3 — Deliver a usable answer
- Grounded answer generation
- Visible evidence stack
- Trace logging and lightweight user feedback
When a policy and an FAQ were both relevant, the workflow was tuned to rank the formal source first. That mattered because the operational value of the answer depended on trust, not just similarity.
Proof the workflow behaved as intended
I did not want the project to stop at “the demo seems to work.” I treated proof as part of the case, combining retrieval evaluation, answer-pack validation, and visible product behavior.
What is the approval flow for a standard business expense above €500?
Can a contractor request company hardware directly from IT?
I’ve already submitted a late expense claim and I’m missing a receipt. Is this likely to be approved?
The most meaningful tests were not the cleanest prompts. They were the more human ones, where the workflow had to combine policy, process, and uncertainty without sounding overconfident.
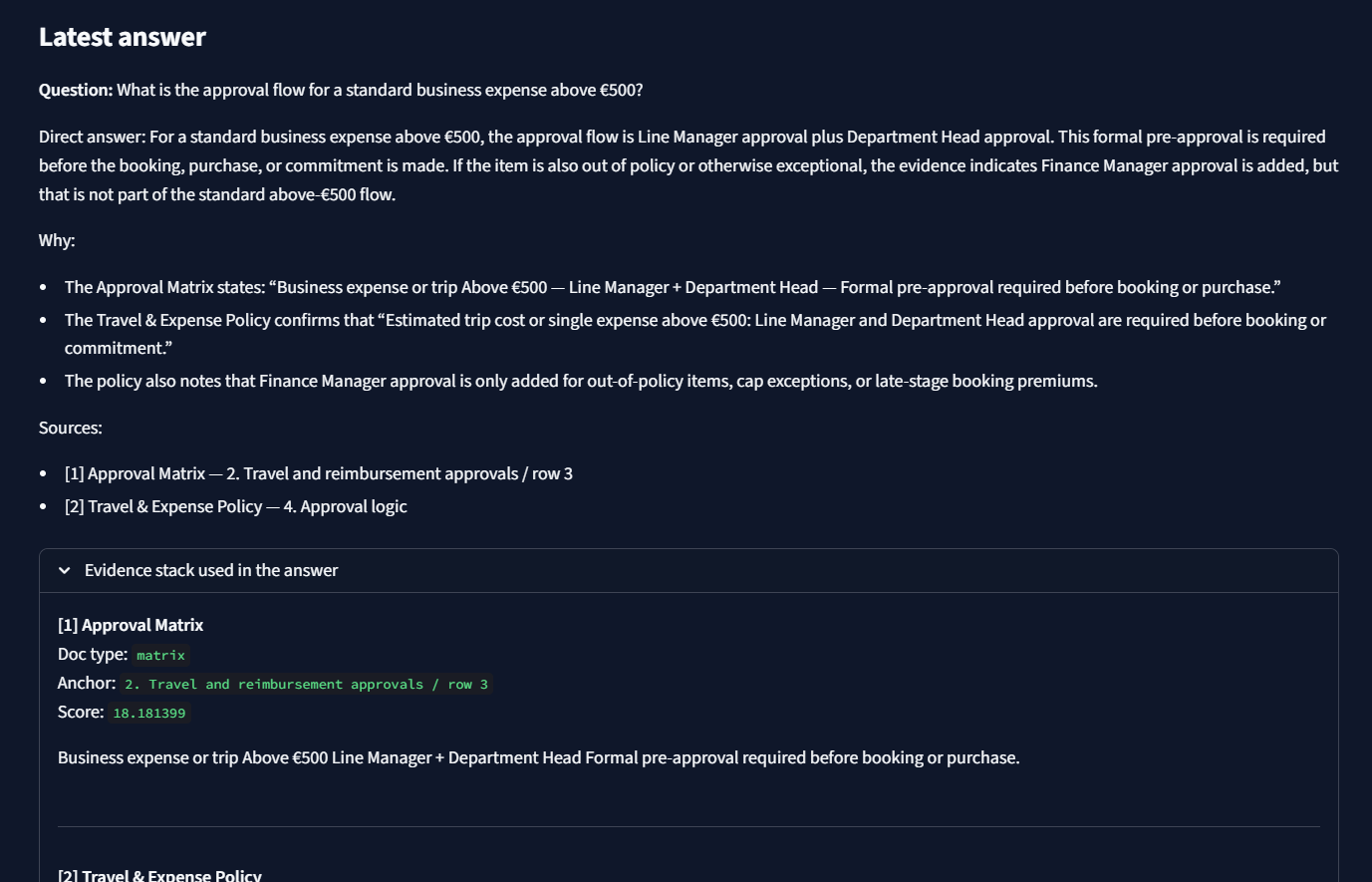
Grounded answer with visible evidence
The workflow returns an answer that is usable in context and anchored to supporting source material rather than sounding right by default.
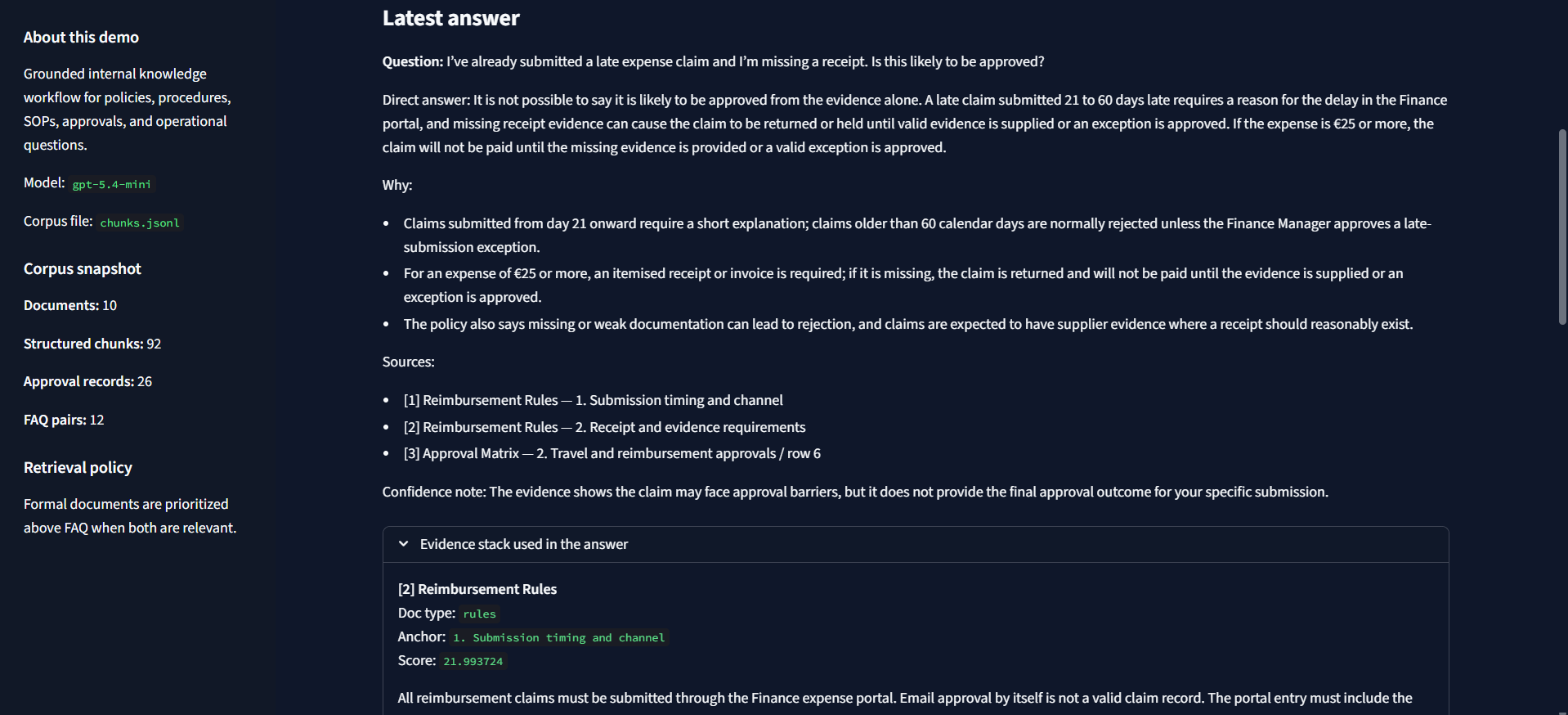
More human and ambiguous operational question
This is where the workflow becomes more believable: the question is less neat, the answer has to stay careful, and the evidence still matters.
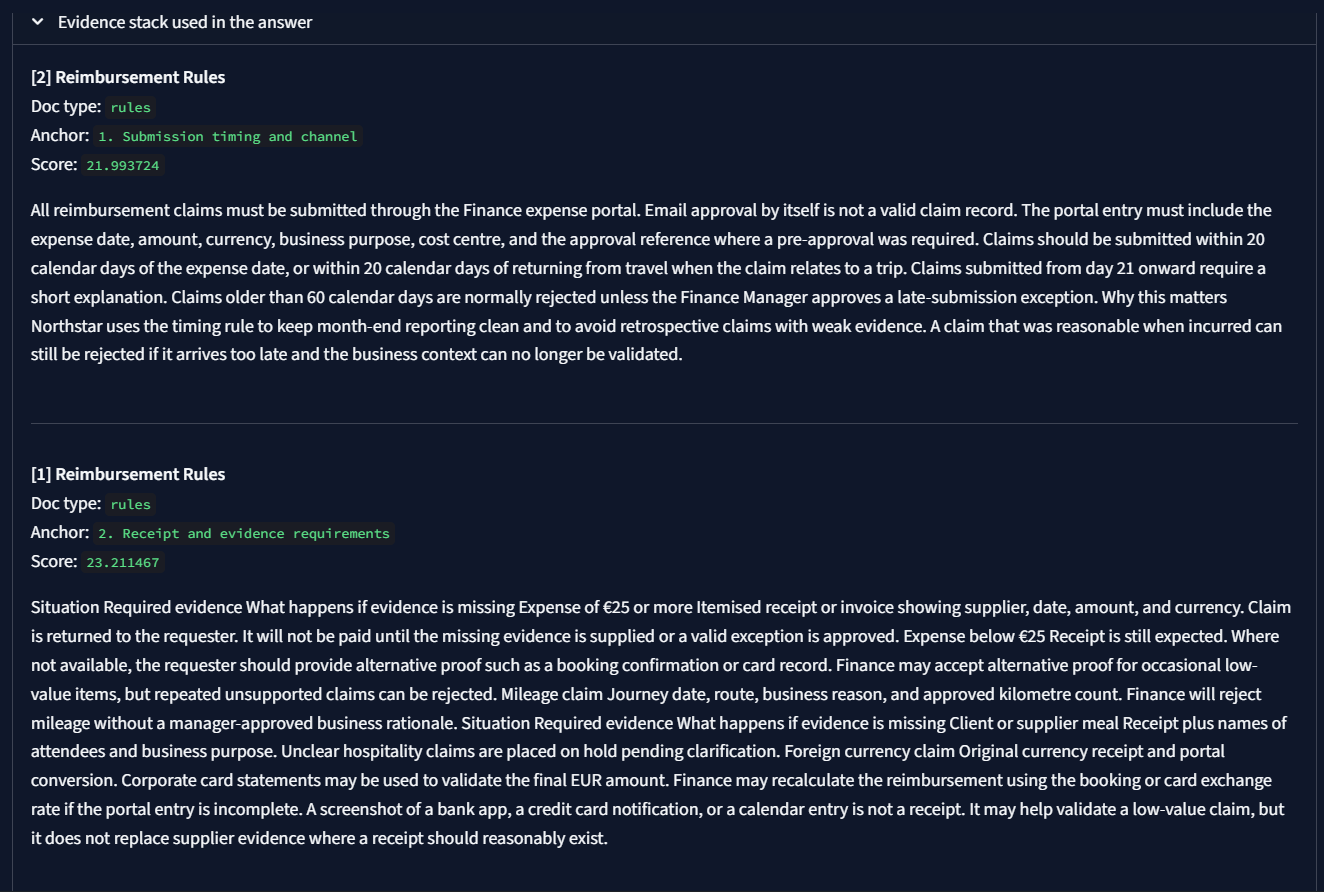
Evidence stack close-up
Trust comes from showing where the answer came from, not just from sounding fluent.
Corpus architecture map
The corpus was designed around authority and process logic, not just document availability.
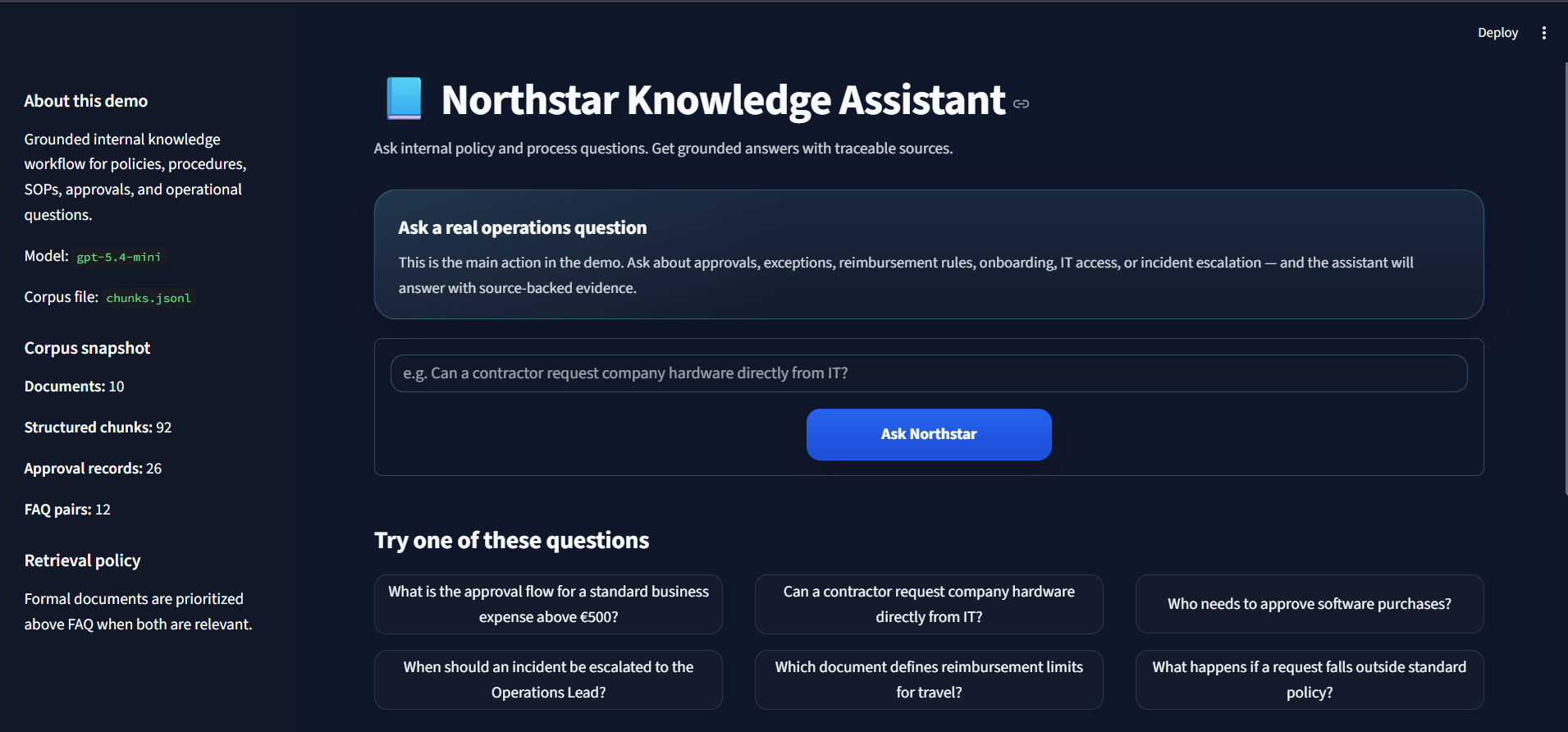
Demo home state
The Streamlit MVP exposed the ask flow, example prompts, corpus stats, and answer workflow in a simple business-facing interface.
Why this case matters
What this says about how I work
- I started from an operational problem, not from AI hype
- I treated corpus design as part of the solution, not as setup
- I built for grounded answers, not just fluent answers
- I used evaluation to test behavior, not just demo appearance
Why it strengthens the portfolio
- Shows applied GenAI relevance without sounding trendy
- Demonstrates retrieval and reranking awareness
- Proves I can package technical systems in business language
- Adds a realistic internal AI workflow case to the portfolio mix
This project matters because it shows that I do not think about GenAI as a flashy interface layer. I think about it as a workflow that only becomes useful when business context, document structure, retrieval logic, and evidence discipline are all doing their job.
Current scope and next iteration
This is still an MVP rather than a production deployment. It does not yet include permission-aware retrieval, document freshness governance, enterprise monitoring, or workflow ownership beyond the prototype boundary.
That said, those are scaling questions, not proof-of-value questions. The project already demonstrates the core point: a grounded internal knowledge workflow can make documentation more usable, answers more consistent, and source visibility much easier to trust.
Next step
Want to explore more of the portfolio or get in touch?
You can go back to the selected projects section or contact me directly by email.